TIRO-Scientific
Piattaforma enterprise di ricerca autonoma per deep research, citazioni verificate e sintesi scientifica ad alta precisione
Panoramica
Visione della Piattaforma
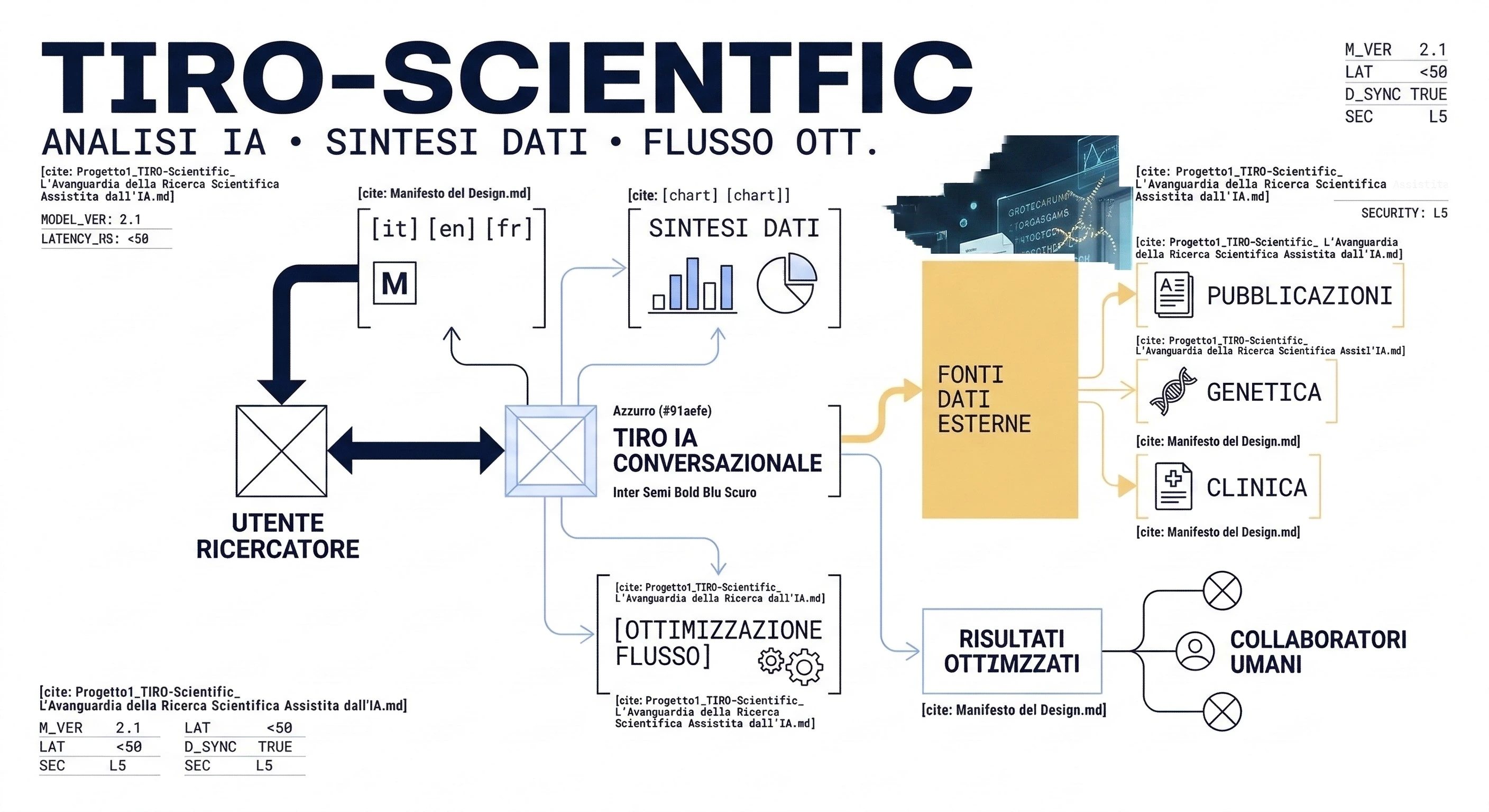
TIRO-Scientific v2.0 non è concepito come un chatbot generico, ma come un assistente di ricerca autonomo di classe enterprise per ambiti accademici e R&D. La piattaforma accelera letteratura scientifica e analisi documentale su centinaia di fonti simultaneamente, trasformando la sintesi bibliografica in un workflow strategico ad alta precisione.
La proposta di valore si fonda su tre pilastri: velocità, connessione di idee complesse e accuratezza documentale, garantita da verifiche multilivello e citazioni verificate.
Agentic Research Pipeline
Il workflow segue una sequenza trasparente: pianificazione iterativa, approvazione dell’utente e stesura autonoma. In questo modo il ricercatore mantiene il controllo strategico, mentre il sistema esegue in autonomia task di deep research ampi e strutturati.
Specifiche tecniche
Architettura di Reasoning
TIRO-Scientific mitiga i limiti di finestra di contesto e di coerenza narrativa dei normali LLM tramite un Reasoning Engine (RLM) gerarchico. Un sistema root agisce da ancora architettonica, preservando la struttura globale mentre sotto-task specializzati generano le singole sezioni.
Stack di Integrità Scientifica
- Lie Detector (RAGLens): monitora inferenze non supportate e aiuta a prevenire le allucinazioni
- Critic a cinque livelli: revisiona ogni sezione per qualità e coerenza prima della finalizzazione
- Targeted retrieval: ricerca automaticamente le evidenze mancanti e riscrive le sezioni deboli
Knowledge Intelligence
- Grafi delle citazioni: mappano le relazioni tra pubblicazioni e identificano i paper chiave
- Clustering semantico: organizza grandi corpora in domini tematici significativi
- Deduplicazione: controlli su metadati, struttura e semantica riducono la ridondanza delle librerie di ricerca
- Export citazioni: supporto per APA, IEEE e BibTeX
Privacy e Controllo
Attraverso la Discover Dashboard, i ricercatori possono interrogare fonti come arXiv, Semantic Scholar e OpenAlex, scegliere il modello più adatto a ogni task e monitorare il consumo di token. Il deployment locale via Docker garantisce che i dati di ricerca proprietari restino all’interno del perimetro di sicurezza dell’organizzazione.
Partner di progetto
Nessun partner indicato.
Cronologia
Pianificazione iterativa e definizione del framework di ricerca governata dall’utente
Stesura autonoma tramite Agentic Research Pipeline
Verifica, targeted retrieval e raffinamento basato su citazioni
Discover Dashboard, graph intelligence e deployment enterprise locale
Galleria
Nessun media disponibile.